🪙 Euro Coin Classifier (ViT)
Fine-tuning a Vision Transformer to recognize Euro coin denominations from images and exposing it via a simple web interface.
Fine-tuning a Vision Transformer to recognize Euro coin denominations from images and exposing it via a simple web interface.
Euro coins share similar shapes and colors, but differ in size, engravings, and design details. Automatically recognizing the coin denomination from an image is a nice testbed for applying modern vision models and evaluating how well they handle fine-grained visual differences.
This project explores how to use a Vision Transformer for this task, instead of a classic CNN, and how to wrap the model into a small, usable app that could be integrated into a larger system (for example a coin-sorting device or an educational tool).
The dataset was split into training, validation, and test partitions to allow proper hyperparameter tuning and evaluation without leaking test information.
The core idea is to use a pretrained Vision Transformer and fine-tune it on the Euro coin dataset. This leverages strong representations learned from large-scale image pretraining while adapting to the specific denominations.
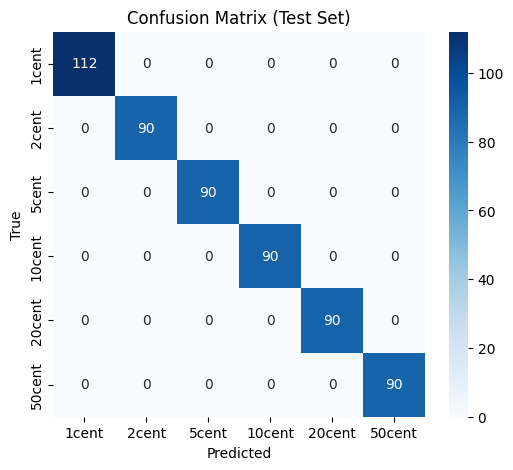
The ViT-based classifier performs extremely well on the test split, with almost no misclassifications between denominations. The confusion matrix is close to diagonal, indicating clear separation between classes.
These results confirm that ViT is a strong choice for fine-grained visual categorization, even on a relatively small but well-structured dataset like Euro coins.
The code is organized so that changing the backbone (e.g. from ViT to a CNN) or adding new denominations is straightforward and mainly requires updating configuration and labels.
Overall, this project was a good exercise in applying transformer-based vision models to a concrete, visual classification task and thinking about deployment beyond just a notebook.